รู้จักกับ Latent Dirichlet Allocation (Part 1)
[อ่านพาร์ทแรกให้จบก่อนนะ 555
รู้จักกับ Latent Dirichlet Allocation (Part 2): https://goo.gl/fQc6AB]
สวัสดีครับทุกคน ในบทความนี้จะอธิบายถึง Latent Dirichlet Allocation (LDA) แปลไทยได้ว่า “การจัดสรรของดีรีเคลแฝง” (อย่าแปลเลย) ซึ่งคนละตัวกับ Linear Discriminant Analysis นะ ถึงแม้จะ LDA เหมือนกัน
ในบทความนี้จะพูดถึง 5 หัวข้อนั่นก็คือ จะบอกปัญหานิดนึง เกริ่นนำอีกหน่อยว่า LDA หรือ Latent Dirichlet Allocation คืออะไร บอกสมมติฐานของ LDA อธิบาย Graphical Model ของ LDA และก็ปิดจบด้วยตัวอย่าง input/output ของ LDA อีกเล็กน้อย ถ้าพร้อมแล้วไปลุยกันเลย
1. Problems
ลองคิดสภาพดูว่า ถ้าเรามีหนังสือหรือเอกสารจำนวนหนึ่ง เราจะทำอย่างไรดีที่เราจะสามารถจัดระเบียบ ค้นหา หรือทำความเข้าใจกับเอกสารเหล่านั้นได้ ซ้ำร้ายไปกว่านั้น ยิ่งจำนวนของหนังสือหรือเอกสารที่มากขึ้นไปเท่าไร ความยากในการจัดระเบียบ ค้นหา หรือทำความเข้าใจก็จะยิ่งยากขึ้นไปอีก แล้วเราควรทำอย่างไรดี ทีนี้ถ้าเราสามารถทำการโมเดลหัวข้อเรื่อง (Topic Modelling) ของเอกสารนั้นได้ เราก็จะสามารถจัดระเบียบ ทำความเข้าใจ ค้นหา และสรุปความจากเอกสารที่มีจำนวนมากมายนั่นได้ โดยหลัก ๆ แล้วถ้าเราจะทำ Topic Modelling แล้ว ก็มี 3 ขั้นตอนคร่าว ๆ คือ
- ค้นหา topic ที่มันอยู่ในแต่ละเอกสาร
- แปะป้ายเอกสารนี้ไว้นะ ว่ามันเกี่ยวกับ topic อะไร
- ถ้าเราต้องการค้นหาหรือสรุปความ เราก็ใช้ป้ายแปะที่เป็น topic ในข้อ 2 มาช่วย เพราะบางทีแล้วถ้าเราค้นหาด้วยคำมันอาจจะเฉพาะเจาะจงเกินไป เลยค้นหาไม่เจอ ค้นหาด้วย topic ก็อาจจะเป็นทางเลือกนึงที่ดีกว่าก็เป็นได้
คำถามต่อมาก็คือ โอเครู้แล้วแหละ ว่าถ้าเราหา topic ของเอกสารได้ ชีวิตก็น่าจะดีขึ้นไม่ทางใดก็ทางหนึ่ง แต่ประเด็นคือเราจะหา topic ได้ยังไงหละ เราต้องมีสมมติฐานอะไรเกี่ยวกับเอกสารบ้าง จากทั้งหมดทั้งมวลนี้เลยเกิดเป็น โกโกครั้นช์ (ไม่ใช่) เลยเกิดเป็น Unsupervised Learning ตัวนึง (มีแค่เอกสารที่มีคำอยู่ข้างในก็โอเคไม่ต้องทำ label ใด ๆ ว่าคำนี้อยู่ topic อะไร) ที่มีชื่อว่า Latent Dirichlet Allocation (LDA) เพื่อใช้ในการทำ Topic Modelling แต่ความวิเศษของมันคือมันเป็น Probabilistic Topic Modelling คือใช้ความน่าจะเป็นมาทำ Topic Modelling มันจะเป็นยังไงไว้ติดตามต่อได้ด้านล่าง
ก่อนจะเข้าสู่เนื้อหา ขอขายของเกี่ยวกับ LDA นิดนึง LDA เป็นงานวิจัยชิ้นนึงที่ออกมาตั้งแต่ปี 2003 โดยใช้ชื่อเรื่องว่า “Latent dirichlet allocation” แต่งโดย David Blei, Andrew Ng และ Michael Jordan ซึ่งผ่านมาแล้วเกือบ ๆ 15 ปี
คุณพระ! (ตกใจแรง) มียอดของการอ้างอิงไปกว่า 23,000 ครั้ง แสดงว่า LDA นี่ก็ classic พอสมควร ถ้ามองผิวเผินแล้ว LDA ใช้ทำ Topic Modelling ก็น่าจะเป็นงานฝั่ง Natural Language Processing (การประมวลผลภาษาธรรมชาติ) ไปเนอะ แต่ทุกวันนี้ LDA ถูกประยุกต์ไปยังงานวิจัยหลายประเภทมาก เช่น Sentiment Analysis (การวิเคราะห์ความรู้สึก), Bioinfomatics (ชีวสารสนเทศ), Recommender System (ระบบแนะนำ) และอื่น ๆ อีกมากมาย (อ่านเพิ่มเติมได้จากงานวิจัยที่อ้างอิง LDA) มาถึงจุดนี้รู้สึกตื่นเต้นที่จะรู้จัก LDA ให้มากกว่านี้หรือยัง ถ้ายังก็ช่วยไม่ได้ ลองมาดูรายละเอียดกันดีกว่า
2. Introduction to LDA
Latent Dirichlet Allocation คือ Latent Probabilistic Model ตัวนึงที่ใช้ในการทำ Topic Modelling โดย Topic ที่กล่าวถึงนี้มันอาจจะเป็น หัวข้อ หรือ theme อะไรบางอย่างที่ซ่อน (hidden) อยู่ในเอกสารและเป็นสิ่งที่เราต้องการ extract มาจากเอกสาร แต่ความพิเศษของ topic เหล่านี้คือมันเป็น Latent Topic มันแฝงหรือซ่อนอยู่ในเอกสาร (บางตำราก็จะเรียกว่า topic เป็นคำกลาง ๆ ว่า Latent Variable หรือ Hidden Variable) แต่เราและคอมพิวเตอร์ไม่เห็นมันตรง ๆ หมายความว่าเราจะบอกได้แค่ว่า คำเหล่านี้อยู่ใน latent topic ที่ 1 2 หรือ 3 และเอกสารนี้มีสัดส่วนของแต่ละ latent topic เท่าไร แต่เป็นหน้าที่ของเราที่จะต้องมากำหนดว่าแต่ละ latent topic นั้นกล่าวถึงอะไร เช่น latent topic ที่ 1 กล่าวถึงเรื่องการเมือง latent topic ที่ 2 กล่าวถึงเรื่องกีฬา ต่างจากคำ (words) แต่ละคำที่เป็น Observed Variables คือเป็นสิ่งที่เราเห็นอยู่แล้วว่าคำนี้คือคำว่าอะไร
อ้าว เห็นมี latent ละ แล้วมันเป็น probabilistic ยังไงอะ? คำตอบก็คือ เราใช้ความน่าจะเป็นในการอธิบาย topic ต่าง ๆ เช่น เอกสารที่ 1 จะมี topic ที่ 1 2 และ 3 กระจายอยู่ด้วยความน่าจะเป็นเท่าไร และใน topic ที่ 1 2 3 นั้น มี คำต่าง ๆ กระจายอยู่ด้วยความน่าจะเป็นเท่าไร (ซึ่งนี่ก็อาจจะเป็นข้อดีของ Machine learning สาย probability เพราะเราสามารถบอกความไม่แน่นอนตรงนี้ได้)
ยิ่งไปกว่านั้น LDA มันก็ถือเป็น Generative Model ตัวนึง หมายความว่า หลังจากการที่เราเรียนรู้ความน่าจะเป็นต่าง ๆ จาก เอกสารและคำ ที่เรามีแล้ว การจะสร้าง เอกสารใหม่ก็ไม่ใช่เรื่องยากอะไร ก็แค่สุ่ม topic และสุ่มคำจาก topic นั้นมาสร้างเอกสารใหม่ สำหรับวิธีการ generate เอกสารใหม่นั้น เค้าก็เรียกกันกลาง ๆ กันว่า Generative Process
ณ ตอนนี้ทุกคนน่าจะมองออกว่า ถ้าเรามี input เป็น หลาย ๆ เอกสารที่แต่ละ เอกสารก็ประกอบด้วยคำจำนวนหนึ่ง ถ้าเราเอา input ตรงนี้ไปใส่ใน LDA มันก็น่าจะคืนผลลัพธ์มาทำนองว่า คำนี้อยู่ topic นี้ด้วยความน่าจะเป็นเท่าไร และในเอกสารนี้จะมี topic ต่าง ๆ อยู่ด้วยความน่าจะเป็นเท่าไร
3. LDA Intuition and Assumption
ในหัวข้อนี้ เราจะมาพยายามเข้าใจ LDA ให้มากขึ้น โดยจะพูดถึง Intuition และสมมติฐานของมันกัน Intuition ที่ง่ายที่สุดของ LDA คือบอกว่าในหนึ่งเอกสารเนี่ย มันประกอบด้วยหลาย topics นะ และหลาย ๆ topic มันก็มีหลาย คำซึ่งแต่ละสีในภาพด้านล่างนั้นก็หมายถึง topic ของคำนั่นเอง
แต่อันข้างบนนี่ก็คร่าวเกิน งั้นเรามาขยายความว่า ไอที่บอกว่า เอกสารมีหลาย topic นี่หมายความว่ายังไง สำหรับ LDA นั้นเค้ามีสมมติฐานเกี่ยวกับโมเดล 3 ข้อคือ
- แต่ละ topic เนี่ยมันประกอบไปด้วยคำหลาย ๆ คำอยู่รวมกันเป็นการกระจายแบบนึง (Each topic is a distribution over words)
- แต่ละ เอกสารเนี่ย มันเกิดมาจากเอาหลาย ๆ topic มายำรวมกัน (Each document is a mixture of topics)
- แต่ละคำในเอกสาร เนี่ยถูกหยิบหรือสุ่มมาจาก topic ข้างบนนี่แหละ
เพื่อความเข้าใจมากขึ้น สมมติถ้าเรามี เอกสารที่ชื่อว่า Seeking Life’s Bare (Genetic) Necessities สิ่งที่เราจะได้จาก LDA ก็คือ
- Topic proportions (กราฟแท่งด้านขวา) ว่าในแต่ละเอกสารเนี่ย มีแต่ละ topic อยู่ด้วยความน่าจะเป็นเท่าไร โดยการกระจายของความน่าจะเป็น (probability distribution) นี้เป็นการกระจายแบบไม่ต่อเนื่อง (discrete) เช่น เอกสารในรูปข้างบนนี้ ประกอบด้วย topic 1, topic 2 และ topic 3 ด้วยความน่าจะเป็น 0.35, 0.5 และ 0.15 ตามลำดับ
- Topics สมมติว่าเรากำหนดไว้ให้เอกสารนี้มี 4 topics แล้วในแต่ละ topics จะมีคำ ๆ นึงอยู่ด้วยความน่าจะเป็นเท่าไร โดยจำนวน topics เป็น Hyperparameter ที่เราต้องจิ้มมาเองว่าจะเอากี่ topic ซึ่งเราอาจจะมีสมมติฐานอะไรบางอย่างหรือลองจิ้มมั่ว ๆ ดู
- พอเราได้ output ในลักษณะนี้แล้ว เราก็ต้องมาทำ post-processing ต่อนิดนึงว่า topic สีแดง มีคำพวก gene, dna, genetics อยู่มันต้องเกี่ยวกับ Genetics แน่เลย ส่วน topic สีฟ้ามีคำว่า data, number, computer ก็น่าจะเป็นเกี่ยวกับ Computer Science
แต่ความจริงชีวิตคงไม่ง่ายเหมือนภาพด้านบนเพราะเรามีแค่ เอกสารกับคำ ซึ่งเป็น observed variable ส่วน topic ที่เราพูดถึงมาตลอดนี้มันเป็น latent variables ที่เราต้องพยายาม infer มาให้ได้จาก observed variable ที่เรามี หรืออีกแง่นึงคือเราจะพยายามจะหาหรือคำนวณกล่องต่าง ๆ ที่มันหายไปจากรูปแรกนั่นเอง
4. Before LDA as a Graphical Model
ก่อนที่จะไป Graphical Model ของ LDA ขอแนะนำตัวละครที่เกี่ยวกับความน่าจะเป็นต่าง ๆ สักนิดนึง ประกอบไปด้วย Multinomial Distribution, Dirichlet Distribution และ Graphical Model
4.1 Multinomial Distribution
หรือแปลเป็นไทยว่าการแจกแจงแบบอเนกอนาม เป็นการกระจายแบบไม่ต่อเนื่อง (Discrete) ตัวหนึ่ง ถ้าใครเคยผ่านสถิติและความน่าจะเป็นตอน ม. ปลายก็จะพอคุ้นกับ Binomial Distribution (การกระจายแบบทวินาม) ที่เป็นการทดลองซ้ำ ๆ กันหลาย ๆ ครั้ง ซึ่งแต่ละครั้งไม่ขึ้นต่อกัน และในแต่ละครั้งมันมีผลออกมาได้แค่สองแบบ เช่น เราโยนเหรียญหัวก้อย 10 ครั้ง เราอยากรู้ว่าความน่าจะเป็นที่จะออกหัว 8 ครั้งเป็นเท่าไร
สำหรับ Multinomial Distribution นั้นเหมือนกับ Binomial Distribution เลย ต่างกันแค่ว่า ในแต่ละครั้งมันมีผลออกมาได้หลายแบบ เช่น ถุง ๆ นึง มีลูกบอล 3 สี คือ เหลือง แดง เขียว หลาย ๆ ลูกปนกัน เราอยากรู้ว่าความน่าจะเป็นที่เราหยิบลูกบอลทีละลูก แบบใส่คืน 5 ครั้ง จะมีความน่าจะเป็นเท่าไรที่จะหยิบได้สีเหลือง 2 ลูก แดง 2 ลูกและเขียว 1 ลูก
4.2 Dirichlet Distribution
Dirichlet Distribution คือ Distribution ของ Distribution (งงสิ 555) คือถ้าเมื่อก่อนเนี่ย Distribution ที่เรารู้จักมันจะเป็นการสุ่มค่า ๆ นึงจาก Distribution เช่น เราหยิบลูกบอลออกมาจากถุงเหมือนตัวอย่างข้างบน แต่ทีนี้เนี่ย Distribution ของ Distribution หมายถึง แทนที่ที่เราจะหยิบออกมาเป็นลูก ๆ เดียวอะ เราหยิบมันมาทั้งถุงเลย ซึ่งแต่ละถุงมันก็จะมี Distribution ที่แตกต่างกันไป เช่น ถุงแรกอาจจะมีโอกาสได้สีเขียวกับสีเหลืองพอ ๆ กัน แต่สีแดงน้อย อีกถุงก็อาจจะมีโอกาสได้สีแดงมาก แต่สีเขียวและเหลืองน้อย
สำหรับสมการด้านล่างนี้ เป็น Probability density function (PDF, ฟังก์ชันความหนาแน่นของความน่าจะเป็น) ของ Dirichlet Distribution อย่าพึ่งตกใจไป สิ่งที่อยากให้สังเกตคือมันจะมีพารามิเตอร์ตัวนึง ก็คือ α ตัวนี้เองมันจะเป็นตัวควบคุมว่า Distribution ที่สุ่มมาจาก Dirichlet Distribution จะมีการกระจายตัวยังไง พอ ๆ กันหมดเลย หรือจะหนักไปที่อันใดอันนึง
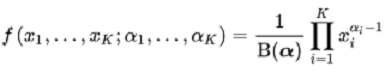
โดยปกติแล้ว สถิติในสาย Bayesian จะใช้ Dirichlet Distribution เป็น Prior Distribution สำหรับ Multinomial Distribution เพราะมันมีสมบัติว่า ถ้าใช้คู่กันแล้ว การแก้สมการจะทำออกได้โดยง่าย เราเรียกคุณสมบัตินั้นว่า Conjugacy โอเค พอก่อน เดี๋ยวคณิตศาสตร์มันจะเยอะเกินไป 555
4.3 Graphical Model
หรือเรียกเต็ม ๆ ว่า Probabilistic Graphical Model มันเป็นแผนภาพหรือภาษานึง ที่ใช้อธิบายพวกความน่าจะเป็นต่าง ๆ สิ่งที่เราจะเห็นได้จาก Graphical Model ก็เช่น ตัวแปรที่ใช้อธิบายความน่าจะเป็นต่าง ๆ (Random Variables) ความขึ้นต่อกัน (Dependency) ทีนี้ Graphical Model โดยทั่วไปมันจะมีส่วนประกอบประมาณนี้
- Nodes and Edges
Node แต่ละอันหรือวงกลมจะใช้อธิบายตัวแปรต่าง ๆ โดยวงกลมนี้จะมีสองสี คือสีขาวและสีเทา วงกลมสีเทานั้นหมายถึงตัวแปรนั้นเป็นตัวแปรที่เราเห็นหรือมีอยู่แล้ว (Observed Variable) ส่วนวงกลมสีขาวจะหมายถึงตัวแปรแฝง (Latent Variable) ที่อาจจะเป็น topic, theme, parameters ที่เราต้องการหา แต่ละ Node ก็จะเชื่อมกันด้วยเส้นเชื่อม (Edges) เพื่อบอกถึงความสัมพันธ์ - Plate Notation
Plate Notation จะเป็นกรอบ ๆ นึงซึ่งข้างในมี Node หรือวงกลมอยู่ แล้วมีตัวหนังสือกำกับไว้ด้วย กรอบนี้จะบอกให้เรารู้ว่า ตัวแปรที่อยู่ในกรอบนั้น มีกี่ตัว อารมณ์ว่าเราเขียนทุกตัวไม่ไหวอะ ก็เลยให้มัน for loop ทุก ๆ element เลยละกัน
ข้อดีอีกอย่างนึงของ Graphical Model คือมันสามารถใช้แทน Joint Distribution ได้ โดยไม่ต้องเขียนสมการยาว ๆ หรือจะใช้แทน Generative Process ที่เขียนเป็นข้อ ๆ เพื่อใช้อธิบายการสร้างข้อมูลก็ได้ คือทั้งสามอย่างนี้ใช้แทนกันได้นั่นเอง อ่านถึงตรงนี้แล้วอาจจะสงสัยว่ามันคืออะไรยังไง งั้นลองมาดูตัวอย่างกัน
ภาพด้านล่างนี้เป็น Graphical Model ของ Normal หรือ Gaussian Distribution ที่มีการกระจายเป็นรูปโค้งระฆังคว่ำที่เราคุ้นชินกันดี โดยค่าแต่ละค่าที่สุ่มมานั้น ขึ้นกับ Mean แทนด้วย μ และ Variance แทนด้วย σ มีเส้นเชื่อม สำหรับ x_n ที่อยู่ในกรอบหมายความว่าค่า x นั้นมีทั้งหมด N ตัว
ณ ตอนนี้ ผมได้เกริ่นถึง LDA มาพอสมควรและแนะนำตัวละครในเบื้องต้นแล้ว พาร์ทต่อไป เราจะลองมาแกะ Graphical Model ของ LDA ว่ามันหมายความว่าอย่างไร Generative Process ของ LDA เป็นอย่างไรแล้วปิดท้ายด้วยหน้าตา input/ output ของ LDA แล้วเจอกันในโพสต์ต่อไป บทความนี้เป็นอันแรกตั้งแต่สมัคร Medium เลย ถ้ามีอะไรผิดพลาดยังไง ก็โพสไว้ด้านล่างได้เลยครับ :)
ต่อพาร์ทสอง: รู้จักกับ Latent Dirichlet Allocation (Part 2): https://goo.gl/fQc6AB]